{kind=link}
Generative AI systems are becoming part of everyday workflows, from writing support to analytics assistance and code review. As adoption grows, one practical challenge keeps showing up: latency. Even strong large language models can feel slow when they must generate long answers token by token. This is where speculative decoding comes in. It is a clever inference-time technique that uses a smaller “draft” model to propose tokens quickly, while a larger “target” model verifies them efficiently. For teams building real-time applications, understanding this method is a useful step—especially for practitioners exploring gen AI training in Hyderabad and looking to connect model theory to production constraints.
Why Decoding in Large Models Is Slow
Most modern language models are autoregressive. That means they produce text one token at a time, and each next token depends on everything generated so far. Even if the model runs on a powerful GPU, the process still involves repeated forward passes. For a long response, those passes add up.
Two factors make the bottleneck worse:
- Sequential dependency: You cannot reliably compute token t+10 before token t+1 is decided.
- Heavy computation per step: Larger models have more layers and parameters, so each step costs more.
Traditional optimisations (quantisation, better kernels, caching key-value attention states) help, but they do not remove the sequential nature of decoding. Speculative decoding tackles the sequential problem by changing how tokens are proposed and checked.
What Speculative Decoding Actually Does
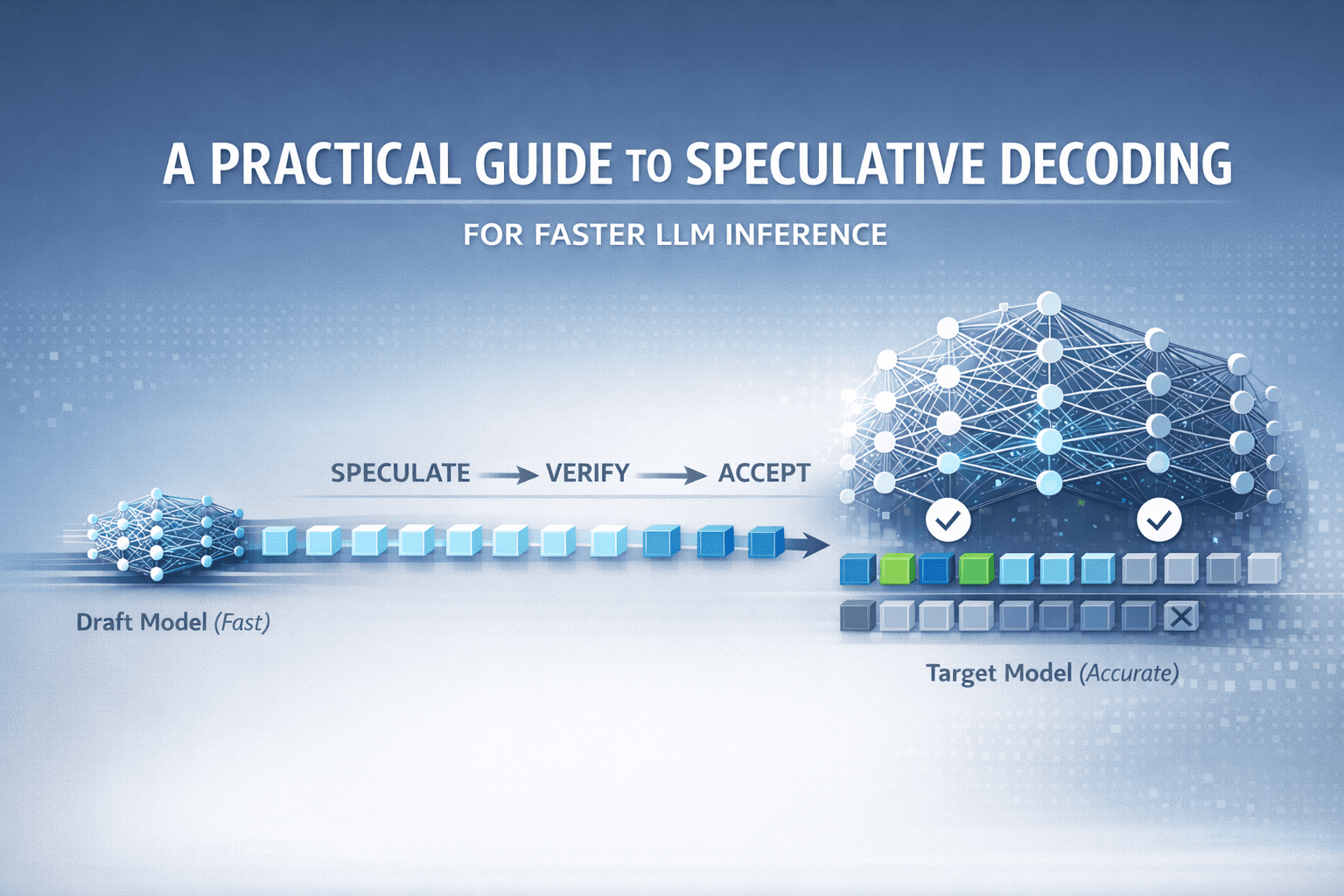
Speculative decoding uses two models:
- Draft model (small): Fast and cheaper. It proposes a short run of future tokens.
- Target model (large): Higher quality but slower. It verifies the proposed tokens in a batched way.
Here is the core idea in simple steps:
- The draft model generates k candidate tokens (for example, 4–10 tokens) using the current context.
- Instead of accepting them immediately, the system sends the full context plus those k tokens to the target model.
- The target model computes probabilities for the same positions and checks whether the draft tokens are acceptable.
- Accepted tokens are kept. If the target model rejects a token at some position, generation falls back to the target model’s preferred token at that point, and the process repeats.
The result: you can sometimes accept several tokens “in one go” rather than forcing the large model to decide every single step independently. When acceptance rates are good, you reduce the number of expensive sequential passes through the large model.
Where the Speedup Comes From (and What Controls It)
Speculative decoding is not magic; the speedup depends on how often the draft model’s guesses match what the target model would have chosen.
Key drivers include:
- Draft model quality: A stronger small model proposes tokens closer to the target model’s distribution, increasing acceptance.
- Token batch size (k): Larger k can increase potential gains, but too large can waste work if many tokens get rejected early.
- Sampling settings: If you use high temperature or very diverse sampling, the draft model may produce more “creative” tokens that the target model rejects. Lower temperature or more conservative sampling can improve acceptance.
- Domain alignment: A draft model fine-tuned for the same domain (support chats, data analysis, coding) tends to align better.
In practice, teams test acceptance rates on real traffic. If acceptance is consistently high, speculative decoding can meaningfully reduce latency while keeping output quality anchored to the larger model. For learners in gen AI training in Hyderabad, this is a great example of how “systems thinking” matters as much as model architecture.
Engineering Considerations in Real Deployments
Implementing speculative decoding well requires more than plugging in two models. A few practical points matter:
- Model pairing strategy: The draft model should be much cheaper per token than the target model, otherwise you lose the benefit. But it must still be good enough to keep acceptance high.
- Caching and memory management: Key-value caching is essential for both models, and memory pressure can become the limiting factor, especially with longer contexts.
- Fallback behaviour: When rejection happens early, the system needs a clean and fast path to continue with the target model without glitches.
- Evaluation beyond speed: Measure quality using task success rates, user satisfaction, and regression tests. Speed improvements are not useful if the output becomes less reliable.
- Observability: Track acceptance rate, average tokens accepted per cycle, latency percentiles, and cost per response. These metrics show whether the technique is actually paying off.
This technique is especially relevant in customer-facing tools where users notice delays quickly, such as chat-based support, analytics copilots, and coding assistants.
How to Learn and Apply It
If your goal is to work on GenAI systems, speculative decoding is a practical topic because it connects probability, sampling, and real-world performance. It also encourages the habit of thinking in trade-offs: speed versus complexity, acceptance rate versus creativity, and GPU usage versus cost.
A good learning path is:
- Understand autoregressive decoding and token sampling.
- Learn inference optimisations (caching, quantisation, batching).
- Study speculative decoding as a layered optimisation on top of these basics.
- Practise by comparing latency and output quality across different draft/target pairs.
For professionals pursuing gen AI training in Hyderabad, adding inference-time optimisation skills can be a differentiator because many teams struggle more with deployment performance than with building prototypes.
Conclusion
Speculative decoding speeds up large-model generation by letting a smaller model propose tokens and a larger model verify them efficiently. When the draft model aligns well with the target model, several tokens can be accepted per cycle, reducing the expensive sequential work that slows decoding. The real value is not only in faster responses, but also in learning how GenAI systems are engineered for production—an essential focus for anyone building practical skills through gen AI training in Hyderabad.